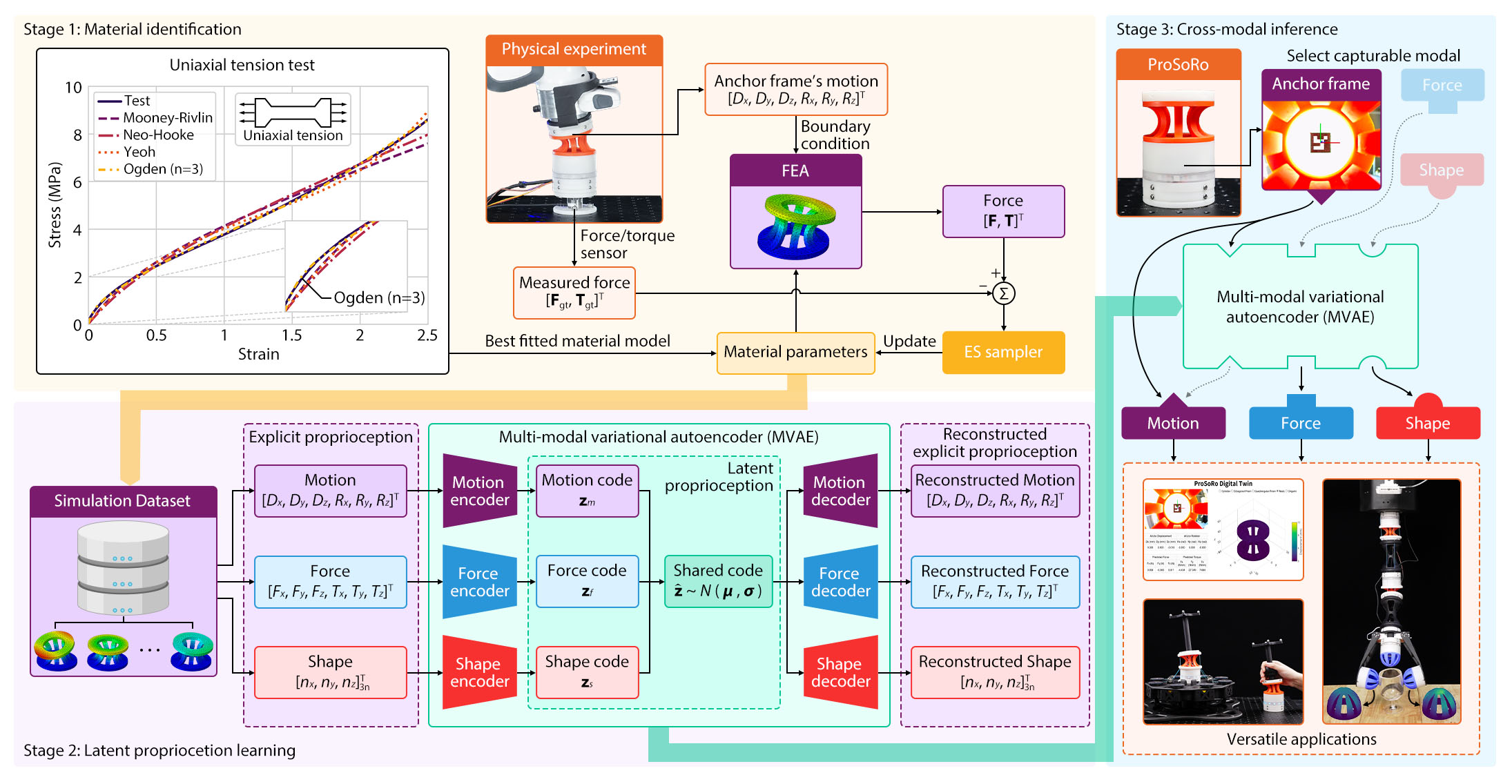
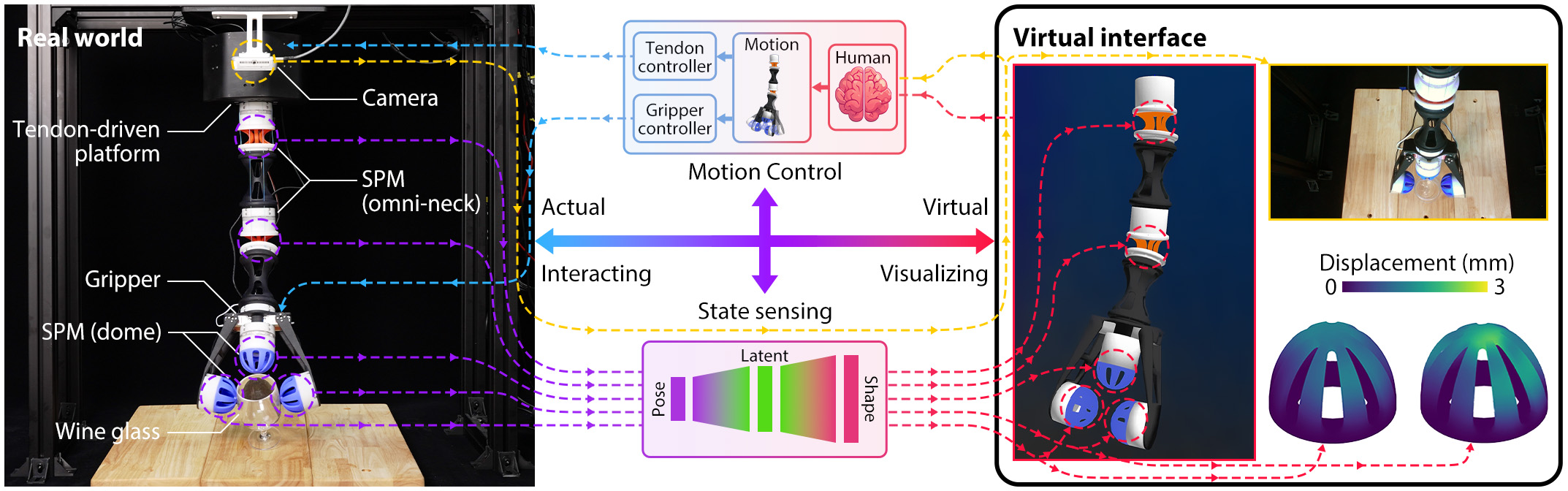
This study introduces an anchor-based approach that leverages a single internal reference frame to infer
the full proprioceptive state of a soft robot, encompassing motion, force, and shape. We developed
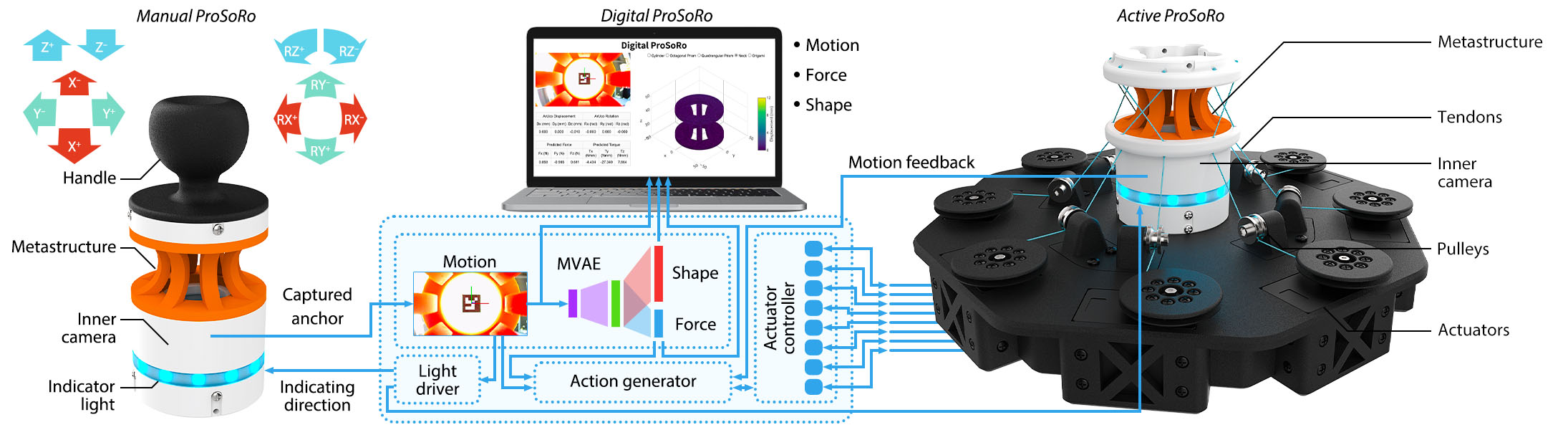
Proprioceptive Soft Robots (ProSoRo), an integrated system that combines soft materials with
embedded sensing capabilities. Each ProSoRo features a metastructure mounted between a top and bottom
frame, with a marker affixed to the top frame serving as the anchor frame. A miniature monocular camera
embedded within the bottom frame tracks the marker's movement in real time. More building details can be
found in hardware guide.
To harness the full potential of this anchor-based approach, we developed a multi-modal proprioception
learning framework utilizing a multi-modal variational autoencoder (MVAE) to align motion, force,
and shape of ProSoRos into a unified representation based on an anchored observation, involving three
stages:
Stage 1: Material identification: Recognizing the impracticality of collecting extensive physical
datasets for soft robots, we leveraged finite element analysis (FEA) simulations to generate high-quality
training data. We begin by measuring the material's stress-strain curve through the standard uniaxial
tension test to obtain the best-fitted material model. Then, we apply an evolution strategy (EVOMIA) to optimize the material parameters by comparing
the calculated force from finite element analysis (FEA) and the measured ground truth from a physical
experiment under the same motion of the anchor point.
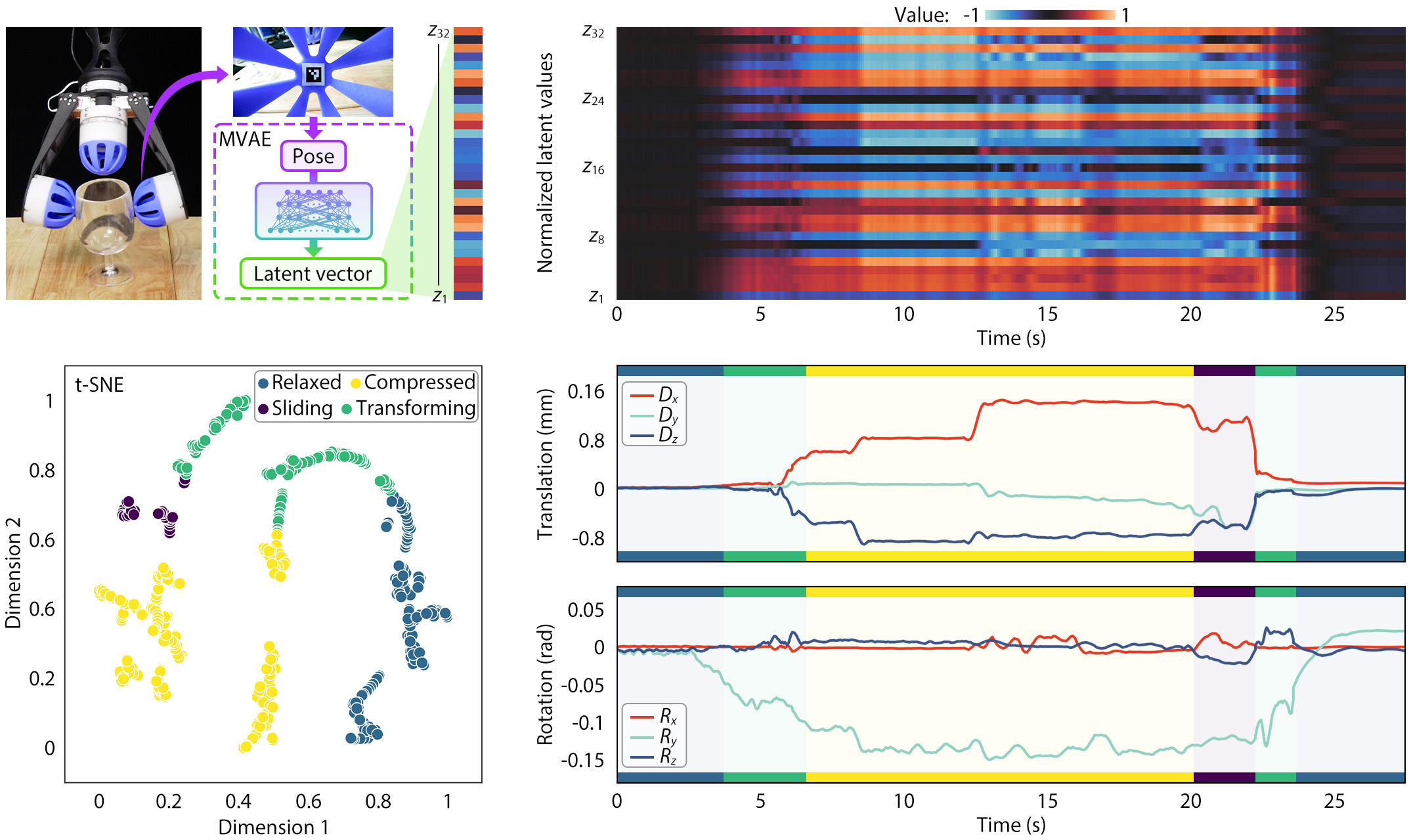
Stage 2: Latent proprioceptive learning: The simulation dataset was generated using the optimized
material parameters and provided motion in $[D_x, D_y, D_z, R_x, R_y, R_z]^\mathrm{T}$, force in $[F_x,
F_y, F_z, T_x, T_y, T_z]^\mathrm{T}$, and shape in node displacements of $[n_x, n_y, n_z]_{3n}^\mathrm{T}$
as the training inputs. To learn these modalities for explicit proprioception, we developed a multi-modal
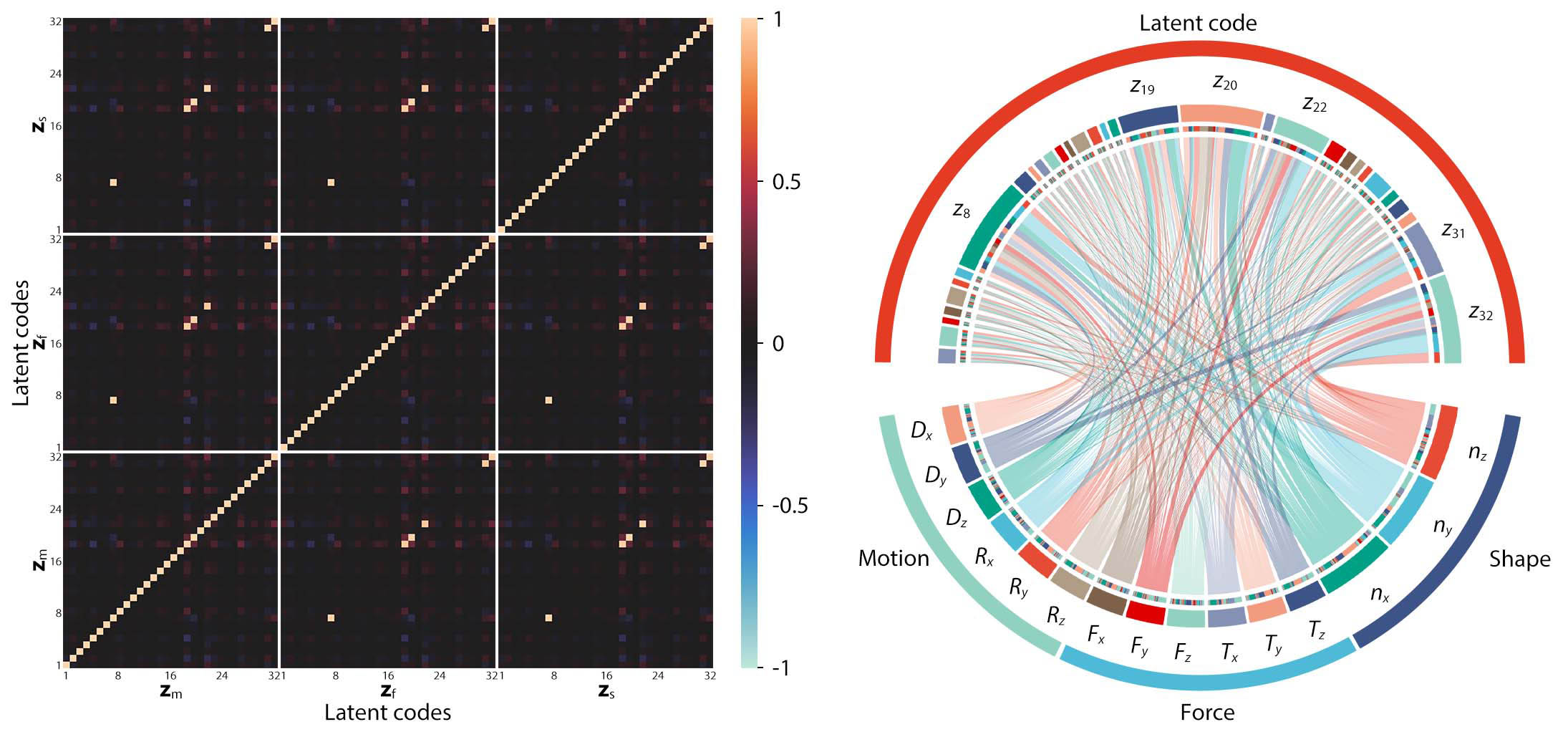
variational autoencoder (MVAE) to encode the ProSoRo's proprioception via latent codes. Three modal latent
codes are generated through three specific motion, force, and shape encoders, and the shared code contains
fused information from all three modalities by minimizing the errors among the three codes. As a result,
the shared codes provide explicit proprioception in the latent space, denoted as latent proprioception,
which can be used to reconstruct the three modalities using specific decoders for applied interactions.
Stage 3: Cross-modal inference: In real-world deployments, the shape modality, for example, can be
estimated from latent proprioception instead of direct measurement, which is usually impossible to achieve
in real-time interactions in robotics. At this stage, we visually capture the ProSoRo's anchor point as
MVAE's input to estimate the force and shape modalities based on the latent knowledge learned from
simulation data. We found that our proposed latent proprioception framework to be a versatile solution in
soft robotic interactions.
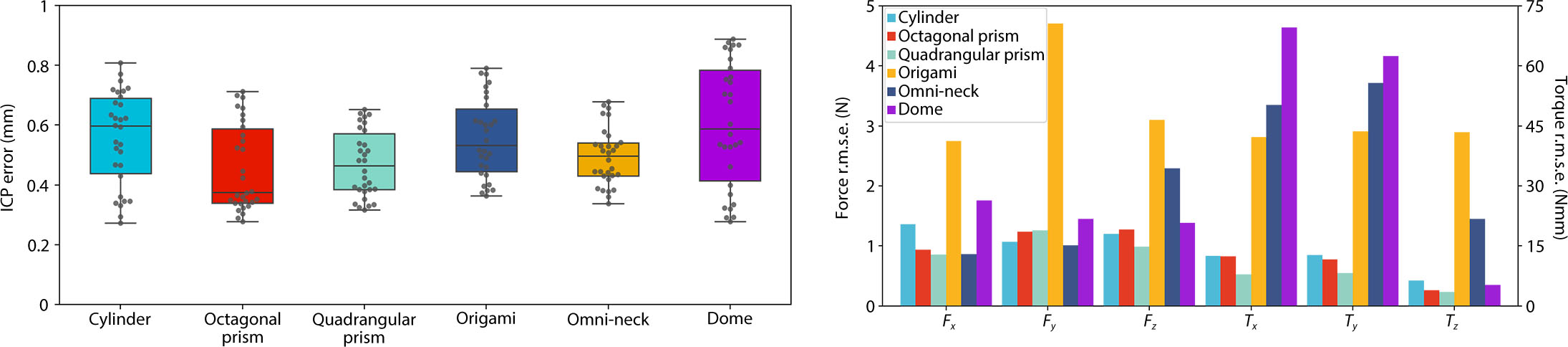
Following the above stages, we realized proprioception on six different shapes of ProSoRos, and the
prototypes are shown below.